Pedestrian Detection using Spatial Haar-like Features
Jinxi Li, Daseul Shim, Longbin Jin, Sehyun Park*, Eunyi Kim
Department of Multimedia Software, Konkuk University, Seoul, Korea
(lijinxi, k201611210, jinlongbin, eykim) @konkuk.ac.kr
*Division of Computer & Communication Engineering, Daegu University, Daegu, Korea
sehyun@daegu.ac.kr
Abstract
In this paper, a simple yet effective detector for pedestrian detection is proposed. The motivation of our method lies in the basic observation that not only the local information but also the global context information is used for more accurately discriminating the people from others in the cluttered background. Therefore, we propose a novel type of feature, called Spatial Harr-like Features (SHFs), to characterize the co-occurrence between one image patch and other image patches. To verify the effectiveness of the proposed method, we evaluate our SHFs on INRIA and Caltech dataset. Experimental results convincingly show that the SHFs are effective to model the geometry context and our pedestrian detector outperforms the published state-of-the-art methods using the HOGs.
Keywords-pedestrian detection; SVM
1. Introduction
Recently, pedestrian detection has become an active research field, and a variety of methods have been developed. However, detecting the people in a cluttered background is still challenging, since different human postures and illumination conditions can cause high variation of human appearances in images. Pedestrian detectors are based on human designed feature maps and auto-generated feature maps which are obtained by deep learning. Here, we concentrated on finding more discriminative features maps among human designed ones and on developing a robust human body model.
In the literature, there are two popularized methods in pedestrian detectors based on human designed features: 1) Papageorigu [1] employed a polynomial support vector machine (SVM) to learn a single pedestrian detector, where Harr wavelets are used as features to describe the full human body; 2) Zhu et al. [4] employed the linear SVM with HOG features as a weak learner in the boosted cascade, where they first generated a number of parts-based detectors with variable sizes and then detected a human if some of all of its parts are presented in the cascade. Then, to improve the detection process, they used only 36-D HOGs from the image patches of different sizes, which allows a near real-time human detection system whereas results in low accuracy detection results.
To compensate the low accuracy in local-patch based detector, LDCFs are designated in [10], where the features are consists of PCA bases of local patches. That is, a LDCF uses learned PCA eigenvectors from training data and showed that top of PCA projections of image patches can be effective for image classification. In [8], a statistical pedestrian shape model is presented, which composed of three body parts such as head, upper body and lower body. Among a number of Harr wavelets extracted from integral channel features, they selected only the binary and ternary rectangle features positioned on the silhouette of their pedestrian shape model, which called as Informed Harr-like features.
In this paper, we propose a novel type of feature, called Spatial Harr-like Features (SHFs), to characterize the co-occurrence between one image patch and other image patches. The proposed method is performed by four steps: HOG-SVM computation, confidence map generation, spatial haar-like feature selection (SHFs), and cascade. We first extract HOG features from image local patch, each of which are learned using linear SVMs as weak classifiers. Thereafter, we select weak classifiers with higher accuracies and then we generate a confidence map, where each cell represents the discrimination power in discriminating the pedestrians from others. Therefore, we can identify some body models which consists of two-pair wises for triple ones of local patches with high discriminative posers, which is called as SHFs. The SHFs can combine global context information using geometric relationships between local texture regions. Finally, the pedestrian detector is generated by traditional boosted cascade of SHFs.
2. Proposed Method
2.1. Weak Classifier Learning
In this paper, we compute the features for the variable size blocks. From the 64x128 detection window, feature vector is calculated for the variable blocks whose size ranges from 12x12 to 64x128 instead of fixed blocks. In total, 5031 blocks are defined in a 64x128 detection window. Thereafter, we divide each block into cells of size 4x4 pixels, and the cell integrated into the block in a sliding fashion, but the cells do not overlap with each other. In the block, each cell consists of a 9-bin HOG features and finally the block contains a concatenated feature vector of all its cells. Then, to extract features vector fast, we use the integral-histogram techniques.
The extracted feature vector is given to SVM, which minimized an upper bound of the generalization error to maximize the margin between the separating hyper-plane. In this paper, totally 5031 feature vectors is trained using a linear SVM, as a weak classifier. As the result of Learning, 410 weak classifiers with high accuracy are selected.
2.2. Confidence Map Generation
From all the learned weak
classifiers, a confidence map is constructed on a OGM, each cell of which has
the confidence value that represents its power in discriminating the target object
from others. The value is obtained by aggregating the detection accuracies of
all weak classifiers that pass on a cell (i,j), ![]() where
where ![]() denotes the number of
weak classifier that are passing on a cell;
denotes the number of
weak classifier that are passing on a cell;![]() is the error of
th weak classifier on a cell. That is, confidence value at a cell is the
average of the accuracy of the weak classifiers containing the cells.
Therefore, the higher confidence is at a cell, it can be seen that weak
classifiers including the cell is more important.
is the error of
th weak classifier on a cell. That is, confidence value at a cell is the
average of the accuracy of the weak classifiers containing the cells.
Therefore, the higher confidence is at a cell, it can be seen that weak
classifiers including the cell is more important.
2.3. Spatial Haar-like Features
To identify key positions with high confidence, we first selects 36 top discriminative weak classifiers composed of 22 from top region and 14 from bottom region. Then by combining the selected weak classifiers from each two high confidence areas in the confidence map, we made a novel feature with geometric relationship, called SHF. A SHF is composed of a pair-wise or a triplet of local image patches that have a strong geometry relationship. The computation of SHF is similar to traditional Haar-like feature. The output value of the SHF can be computed by the following formula:
![]() , k=2 or 3
, k=2 or 3
,
where ![]() is the confidence
value of ith local patch, which are computed by accumulating
the confidence values of cells within the image patch. Then,
is the confidence
value of ith local patch, which are computed by accumulating
the confidence values of cells within the image patch. Then, ![]() is determined by
different mechanisms according to the feature space. For the single-dimensional
features, the sum of the features in the local patch is used, otherwise the
classification results is used. That is, for the multi-dimensional features,
the results after feeding to SVM are used as
is determined by
different mechanisms according to the feature space. For the single-dimensional
features, the sum of the features in the local patch is used, otherwise the
classification results is used. That is, for the multi-dimensional features,
the results after feeding to SVM are used as ![]() .
.
For each SHF, the optimal threshold classification function is determined, such that the minimum number of examples are misclassified. Thus, SHF is represented as:
![]()
,
where ![]() is
SHF value evaluated from results of weak classifiers and
is
SHF value evaluated from results of weak classifiers and ![]() is a threshold.
is a threshold.
|
|
|
|
|
|
|





Fig. 1 Some examples of SHFs
Fig.1 shows some examples of SHFs selected depending on the process of Adaboost. By representing the human body model with these SHFs, we can handle the detection of people with a variety of poses.
Instead of learning all the SHF making into a strong classifier, we use the cascaded classifier composed of a boosted classifier for each stage as an efficient classifier. In order to prevent wasting time, we propose a new method for selecting reasonable SHFs of all possible SHFs.
2.4. Cascade
This section describes an algorithm for constructing a cascade of classifiers which achieves increased detection performance while radically reducing computation time. In this paper, we use a standard cascade approach. For each stage of the cascade we construct a strong classifier consisting of several weal classifier corresponding to SHF among 193 weak classifiers resulted from clustering. In each stage of cascade we keep adding weak classifiers until the predefined quality requirements are met. In our case we require the minimum detection rate to be 0.98 and the maximum false positive to be 0.7 in each stage.
3. Experiments
To assess the validity of the proposed method, the experiments with well-known datasets were performed. Among publicly used datasets, two datasets were considered in our work: INRIA dataset and Caltech dataset. Then, to evaluate its performancer, four metrics were used: precision(PR), detection rate(DR), accuracy rate(AR) and miss rates versus false positives per window (FPPW).
Table 1 shows the experimental results of the proposed method, where it was compared to HOG + SVM [1] and HOG-cascade detectors [2]. They were also compared in terms of a per-window approach to compare the methods, which is shown in Fig. 2.
|
Table 1. Comparing to HOG-SVM and HOG-cascade
.
Fig. 2 Miss rate versus false positive per window curves shown for other approaches |
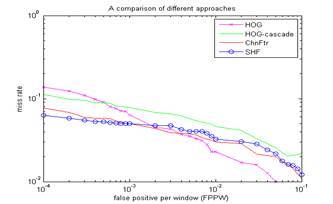
As shown in Table 1 and Fig. 2, the HOG-SVM that use a global window to identify human body has the highest AR of 96.97%, whereas HOG-cascade has showed the lowest AR of 96.07%. Then, the proposed method has similar performance with HOG-SVM, but it has the fastest speed than other methods.
4. Conclusions
We study the question of robust features for pedestrian detection. We propose a new mid-level feature, called Spatial Haar-like feature (SHF). As local features corresponding to a weak classifier, we use linear SVMs with HOG features computed on variable sized blocks. To reduce the computation in weak classifiers with slightly high dimensional feature, a few weak classifiers with high accuracy are selected and computed only for them. From the selected weak classifiers, we found that there is spatial relationship appearing to top and bottom regions. Based on this fact, we finally selected the best weak classifiers including that regions and generate SHF by combining them. Then, we learn the SHF using boosted cascade detector.
References
[1] N. Dalal and B. Triggs. Histograms of orented gradients for human detection. In CVPR, 2005.
[2] Q. Zhu, M.-C. Yeh, K.-T. Cheng, and S. Fast human detection using a cascade of histograms of oriented gradients. In CVPR, 2006.
[3] P. Doll´ar, Z. Tu, P. Perona, and S. Belongie. Integral channel features. In BMVC, 2009.
[3] M. Smith, “Title of paper optional here,” unpublished
[4] P. Doll´ar, C. Wojek, B. Schiele, and P. Perona. Pedestrian detection: an evaluation of the state of the art. IEEE Trans. PAMI, 34(4):743–761, 2011.
[5] P. Doll´ar, R. Appel, and W. Kenzle. Crosstalk cascades for frame-rate pedestrian detection. In ECCV, 2012
[6] P. Viola and M. J. Jones. Robust real-time face detection. IJCV, 57(2):137–154, 2004.
[7] L. Bourdev and J. Brandt: Robust object detection via soft cascade. In CVPR, 2005
[8] S. Zhang, C. Bauckhage, and A. B. Cremers. Informed Haar-like features improve pedestrian detection. In CVPR, 2014
[9] S. Zhang, R. Benenson, B. Schiele. Filtered Channel Features for Pedestrian Detection. In CVPR, 2015
[10] W. Nam, P. Dollár, and J. H. Han. Local decorrelation for improved detection. In NIPS, 2014.